2016/03/06(日)にオフラインミーティングなどやります@東銀座
今回は3つの集まりの合同ミーティングということで、簡単に紹介します。
F#談話室
イベントのパブリックな説明は『.NET Framework用の関数型言語F#について話したりする会です。特に目的は限定していないゆるい集まりです。お気軽にご参加ください。F#をこれから学んでみたいという方も、F#を日々使いこなしている方も 是非参加していただければと思います。』です。
2014年半ばまでは7shiさん主催で池袋で開催されてましたが、その後 @yukitos さんにバトンタッチして、不定期に開催される感じになっています。
yukitosさんは海外のF#コミュニティと積極的につながりをもたれている方でして、海外F#erがゲストとしてやってくることもあったりします。もちろん国内F#erもふらっと来てくれます。F#を実戦投入している @u_1roh さんのような方もいらっしゃることもありますし、興味深いですよ。
CoreCLR読書会
@atsushieno さんが開いてるやつです。クロスプラットフォームな.NET実装であるCoreCLRとその関連コードのソースを読んだり(OSSです)ビルドしたりドキュメントを読んだりしながら談話する会です。CoreCLRのとあるドキュメントを日本語訳しようぜ、というBook of the Runtime日本語訳プロジェクトのオフラインミーティングでもあります。
.NET Fringe Japan (仮)ミーティング
.NET Fringeというのは米国はポートランドで昨年開催され、今年も4月に開催される.NET系技術カンファレンスです。
特徴は《breaking the rules and pushing the boundaries》というところで、.NETのOSSコミュニティ生まれの技術に主眼を置いています。
ちなみにfringe (フリンジ:周辺、境界) という単語のニュアンスはWikipediaの「境界科学」ページあたりを読むとわかったような気になれます。
で、そういうカンファレンスを日本でもやらないか?ということで発足したのがこの会です。
メンバーは今のところ、@yukitosさん、@atsushienoさん、あと私ほか数名です。
RyuJITのSIMD関連コードリーディング(1)
しつこくこの話題。
System.Console.WriteLine("Vector<double>.Count=" + Vector<double>.Count); System.Console.WriteLine("Vector<float>.Count=" + Vector<float>.Count);の結果が
Vector<double>.Count=2 Vector<float>.Count=4になってる(要は、128ビットと判定されてる)
Re: Re: Re: OpenCLやる前にSIMD使い切れっていう幻想 - 猫とC#について書くmatarilloの雑記
ということで、RyuJITのコードを覗き見。
// Get the number of bytes in a SIMD Vector. unsigned getSIMDVectorRegisterByteLength() { #if defined(_TARGET_XARCH_) && !defined(LEGACY_BACKEND) if (canUseAVX()) { return YMM_REGSIZE_BYTES; } else { assert(canUseSSE2()); return XMM_REGSIZE_BYTES; } #else assert(!"getSIMDVectorRegisterByteLength() unimplemented on target arch"); unreached(); #endif }coreclr/src/jit/compiler.h#L6921-L6938
ふむ、canUseAVX()関数がtrueを返すなら、定数YMM_REGSIZE_BYTES(32バイト)が返ってくるようなコードになってますね。
では、canUseAVX()関数はどうなってるかというと。
bool canUseAVX() const { #ifdef FEATURE_AVX_SUPPORT return opts.compCanUseAVX; #else return false; #endif }coreclr/src/jit/compiler.h#L7030-L7037
どんどん深くなってきました。で、今度はopts.compCanUseAVXです。こちらはstructになってます。
opts.compCanUseAVX = false; if (((compileFlags & CORJIT_FLG_PREJIT) == 0) && ((compileFlags & CORJIT_FLG_USE_AVX2) != 0)) { static ConfigDWORD fEnableAVX; if (fEnableAVX.val(CLRConfig::EXTERNAL_EnableAVX) != 0) { opts.compCanUseAVX = true; if (!compIsForInlining()) { codeGen->getEmitter()->SetUseAVX(true); } } }coreclr/src/jit/compiler.cpp#L1608-L1621
だんだん面倒になってきたなあ。ConfigDWORD.val()はここで、CLRConfig::EXTERNAL_EnableAVXはここ。
いやまて、compileFlagsの方が重要か。
unsigned compileFlags = opts.eeFlags;
coreclr/src/jit/compiler.cpp#L1581
unsigned eeFlags; // flags passed from the EEcoreclr/src/jit/compiler.h#L7122
EE(Execution Engine: 実行エンジン)きたー!!!!
続きはまた今度!
Re: Re: Re: OpenCLやる前にSIMD使い切れっていう幻想
2つ前の私の記事で拾ってるツイートが全然関係ないものだったという指摘(すみません、申し訳ない)と、まともに計算できてないというバグの修正をしていただきました。ありがとうございました!
今回使ったのは System.Numerics.Vectors.Vector<T> でした。これはSIMDのビット長と型Tのビット長からいい感じに内部の配列長を決めてくれるもの……らしかったんですが、どうも、RyuJIT RTMでもやはりこのあたり(↓)がまずいらしく。
SIMD is only taking advantage of SSE2 hardware, currently. Due to some implementation restrictions, the RyuJIT CTP cannot automatically switch the size of the type based on local hardware capability. Full AVX support should arrive with a release of the .NET runtime that includes RyuJIT. We have prototyped this, but it just doesn’t work with our CTP deployment model.
http://blogs.msdn.com/b/dotnet/archive/2014/04/07/the-jit-finally-proposed-jit-and-simd-are-getting-married.aspx
System.Console.WriteLine("Vector<double>.Count=" + Vector<double>.Count); System.Console.WriteLine("Vector<float>.Count=" + Vector<float>.Count);
の結果が
Vector<double>.Count=2 Vector<float>.Count=4
になってる(要は、128ビットと判定されてる)っていうのに気付いてない能天気なコード。いやこれはしょぼい。(エラーチェックちゃんとしろということでした)
(さらに追記)AVXのYMMレジスターは256ビットなのですが、ちゃんと256ビット演算をするにはお作法があるので、もしかしたらRyuJITがその作法にのっとってないのかもしれません。たとえば、AVXにもSIMD組み込み関数があるらしいのですが、それを使うと128 ビット演算になるとのことで、そういうコードになってるのかも。わかりませんが。
(さらにさらに追記)System.Numerics.Vector<T>をリフレクションでちょろちょろ見てみたら、一部のメソッドやプロパティには[JitIntrinsic]っていうinternalなカスタム属性がついてて、いちおうILも用意されてるけれども、たぶんここはハードウェアが適合する場合にJITがSIMD関連のコードに置き換えるんだろうなと想像しました。で、Countプロパティにもその[JitIntrinsic]という属性がついてました。当然ですね。
(2016年5月にまた追記)自分のとこのCPUは Core i5-2410M だったのですが、これってつまりSandy Bridgeでして、Sandy Bridge世代でのAVX演算は(中略)128bitずつ2回に分けて演算を行なうという話があるので、128bit判定されたのは単にそれが理由かもしれません。つまり、Haswellアーキテクチャ以降なら256bit判定されるかも。いずれ試します。
結果は青子守唄さんのとこを見てほしいですが、期待したほどには速くならなかったよとのこと。
そうですねえ、青子守唄さんがご自身で書いている通り、メソッド呼び出しコストがあんまり無視できない状態ですね。単に計算すれば速いところをデリゲート経由にしてますから。引数がstructなんでコピーにも若干のコストがかかると思います。
そもそも、本当はVector4d (256ビット) が使えて、それで4次元数の掛け算でも足し算でもいっぺんにやったほうがいいのですが、現状128ビットだとそれもね。Vector4fで精度を落とすのはそれはそれで意味がない。
とりいそぎデリゲートをやめてみました。
https://github.com/matarillo/simd/tree/d443cdd92c40718ec9d1ff0084078e62829adb55
kenta@ASPIRE3830T C:\Users\kenta\Desktop\simd\cs\simd\bin\x64\Release > .\simd Normal: 4638 [ms] Simd: 2927 [ms]

それでも倍にはならないですね。
(さらに追記)青子守唄さんも同じようにコードを書き換えて、メソッド呼び出しがなくなるようにした模様。(青子守唄さんの場合はVector<double>.Countの結果で丁寧に分岐して、それぞれ最適なコードが実行されるようにしてますが)
ちなみに自分のとこのCPUは前にも書いたのですが、SIMDに関係するところで言うと
kenta@ASPIRE3830T C:\Users\kenta > \Binaries\SysinternalsSuite\Coreinfo.exe |grep -E "SSE|AVX" Coreinfo v3.31 - Dump information on system CPU and memory topology Copyright (C) 2008-2014 Mark Russinovich Sysinternals - www.sysinternals.com SSE * Supports Streaming SIMD Extensions SSE2 * Supports Streaming SIMD Extensions 2 SSE3 * Supports Streaming SIMD Extensions 3 SSSE3 * Supports Supplemental SIMD Extensions 3 SSE4a - Supports Streaming SIMDR Extensions 4a SSE4.1 * Supports Streaming SIMD Extensions 4.1 SSE4.2 * Supports Streaming SIMD Extensions 4.2 AVX * Supports AVX intruction extensions
です。
Windows 8と2012 ServerのRegistered I/Oについての記事
IOCPとRIOのイメージを書いてみた。技術的にはあんまり正しくないと思うけど。

RIOは最初こう書いてみたものの

書き直してみた。どっちにしろ正しさは保証できない。

技術的にちゃんとしてる説明は、まずはMSDN。
- What's New for Windows Sockets
- https://msdn.microsoft.com/en-us/library/windows/desktop/ms740642.aspx#Updated_for__Windows_8_and_Windows_Server_2012
でも英語。
それから、Channel9にBUILD 2011のときの動画があるからそれを観ろと。
- New techniques to develop low-latency network apps
- https://channel9.msdn.com/events/Build/BUILD2011/SAC-593T
でも英語だし、時間かかるしなあ。
非公式だけどThe Server FrameworkというC++の有償フレームワークがあって、そこのブログがいろいろ解説記事を書いてる。
- Winsock Registered I/O Archives
- http://www.serverframework.com/asynchronousevents/rio/
やぱりこれも英語。
読み始めるならこのあたりからか。
- Windows 8 Registered I/O Networking Extensions
- http://www.serverframework.com/asynchronousevents/2011/10/windows-8-registered-io-networking-extensions.html
- Windows 8 Registered I/O and I/O Completion Ports
- http://www.serverframework.com/asynchronousevents/2011/10/windows-8-registered-io-and-io-completion-ports.html
後者の方について適当翻訳をしてみた。気が向いたら他の記事も見てみる。
Windows 8のRegistered I/OとI/O完了ポート
前回のブログ記事でWindows 8のRIOネットワーク拡張を紹介した。RIOで処理の完了を受け取るには3つの方法がある。ポーリング、イベントドリブン、そしてIOCPを使う方法。RIOは柔軟だからいろんな形で使える。ポーリングは高速なUDPとかHFTとかでCPUを使い切れてうれしい。イベントドリブンはスピンロックしなくていいから効率的だけど、今一番興味があるのはIOCPスタイル。普通のネットワーク処理ではこれが一番パフォーマンスがいいんじゃないかな。たぶんだけど。
ちなみにこれらの記事は俺の前提とか直感とかに基づいてるし、SDKとかと同期してるわけじゃないよ。まあ話半分で聞いてくれ。
で、RIOとIOCPを合わせて使うには。
RIOの場合は処理の完了はキューに入る。固定長のデータ構造で、ユーザー空間とカーネル空間で共用されるからユーザーモードでデキューできる(詳しくはBUILDのビデオ観れ)。前回も書いたけど、完了をどうやって受け取るかはキューを作るときに指定する。イベントを渡すか、IOCPを渡すか、何も渡さない場合は自分でポーリング。IOCPなら、あらかじめRIONotify()を呼んでおくと、GetQueuedCompletionStatus()でキューが空だったらI/Oスレッドがプールに戻されて、キューが空じゃなくなると通知が来て処理が続く。サンプルコードはこんな感じ。マジで使うならcompletionKeyとかいろいろやることあるかんね。
if (::GetQueuedCompletionStatus( hIOCP, &numberOfBytes, &completionKey, &pOverlapped, INFINITE)) { const DWORD numResults = 10; RIORESULT results[numResults]; ULONG numCompletions = rio.RIODequeueCompletion( queue, results, numResults); while (numCompletions) { for (ULONG i = 0; i < numCompletions; ++i) { // deal with request completion... } numCompletions = rio.RIODequeueCompletion( queue, results, numResults); } rio.RIONotify(queue); }
で、空じゃなくなったら通知されると言ったが、RIONotify()につき通知は1回きり。RIODequeueCompletion()でデキューした後で、次のIOCP完了を受け取りたければふたたびRIONotify()を呼ぶんだ、いいね?面倒なようだけどもこれはこれでいいんだよ。完了キューにアクセスするスレッドを自分で制御できる(訳者メモ:たぶん、RIONotifyを呼び出したスレッドと、引数として渡したキューとが紐づけられるんだろうと思った)から競合とか考えなくていいんだから。送信と受信で1個ずつキューを使って、それぞれ別スレッドにしてもいい。送受信でキューを1つしか使わなければ、あるソケットに紐づくのは同時には1スレッドだけってことになる。普通のIOCPはスレッドプールを使うから、そこが違う(訳者メモ:ひとつのI/Oが完了すると必ずひとつのスレッドが割り当てられるから、複数のI/Oが絡むと必ずマルチスレッドになる)。
RIOのメリット
順序制御が楽、マジで楽。完了キューには期待した通りの順序で入ってくるから、1スレッドでアクセスすれば期待した順序で取り出せるでしょ?IOCPでも通知は順番通りだけど、スレッドプールのせいで順序制御に余計な手間がかかることを考えれば、RIOの方が簡単。あとRIOには送受信バッファがない。(訳者メモ:そのあとも何かちょっと書いてあるけど読み飛ばし)
他のメリットは1スレッドで続けてデキューできること。デキューしてる間はカーネルモードに遷移する必要もないし、キューが空になってからカーネルモードに入る的なやつで、いい感じ。
RIOのデメリット
I/Oスレッドをフル活用するのは大変だよーん。キューの数とかスレッドの数とかは自分で制御することになるわけだし。一般的な用途ではRIOを生で触るのは辛いから、そういうときは、新しいコネクションをどのキューに割り振るかとか、キューの増減どうするかとか、そういうのをやってくれるフレームワーク的なものが欲しい。キューの数が増えてるにもかかわらずI/Oスレッドが足りない場合、1スレッドの処理を1つのキューにかかりきりにすると、スレッドが割り当たってないキューのコネクションはいつまでも待たされてしまうけどそれでいいの?って話もある。
それから、I/OスレッドがRIONotify()を呼ぶ前にうっかり別の処理でブロックしてしまったりすると、そのキューで扱うソケットは全部待ちになってしまうから、他の接続に迷惑をかけることになるよ。
Re: OpenCLやる前にSIMD使い切れっていう幻想
注意:この記事のコードにはバグがあってまともに動いてません。詳細はこの記事やこの記事を読んでください。
(C#は・・・まぁ、RyuJITが使えるようになればマシになるのかな)
OpenCLやる前にSIMD使い切れっていう幻想 - aokomoriuta's blog
青子守唄さんのC#コードはそもそもSIMDが有効になってないんですよね。
2015-05-01にもある通り、System.Numerics.VectorsをNuGetで落としてこないといけない。
なので、いまさらですが、.NET Framework 4.6のRyuJITでSIMDを試してみましたよ。
コードは(bitbucketでもいいのですが)GitHubに置いてあります。
- リポジトリ
- https://github.com/matarillo/simd/tree/39642fc623d8f6c841ac1f7c50e26a2fdcd90cd9
- C#のコード
- https://github.com/matarillo/simd/blob/39642fc623d8f6c841ac1f7c50e26a2fdcd90cd9/cs/simd/Simd.cs
環境
- OS: Windows 10 Insider Preview Build 10532 (日本語でコルタナがうごくやつ)
- CPU: Intel(R) Core(TM) i5-2410M CPU @ 2.30GHz
- GPU: (Intel HD Graphics 3000だけど今回は関係ない)
- RAM: DDR3-1066 4GBx2
- ビルド環境:Visual Studio 2015, .NET Framework 4.6
- ビルドオプション:Release, x64
結果
kenta@ASPIRE3830T C:\Users\kenta\Desktop\simd\cs\simd\bin\x64\Release > .\simd.exe Normal: 4691 [ms] SIMD: 1394 [ms] Parallel SIMD: 1169 [ms] Press Any key...
コードみるとわかりますが
Parallel.For(0, n, i =>
{
var a = f[i] * rm;
x[i] += v[i] * dt + a * tmp;
v[i] += a * dt;
});
こんなんで4倍程度速くなるので、「C#でいいじゃん」という気にもなりますね。ああもちろんF#でもVB.NETでも同じような恩恵は得られますが。冒頭にも書きましたが、このコードにはバグがあったのでぜんぜんまともな結果を出せていません。
ちなみにWindowsマシンを持ってなくて、MacやLinuxのMonoを使って試してみたい人は、Mono.Simd名前空間の型を使うように修正してくださいね。RyuJITの取り込みはまだ作業中のはずなので。
追記
まあたしかに連チャンで実行するとキャッシュに乗りますね。その辺対処したコードを後で載せましょう。
とりいそぎ画像だけ

もしかしてだけど、jのループが消えてるのがレギュレーション違反って言ってるのかな。
たとえばこういうこと?
struct NaiveVector4 { public double X0; public double X1; public double X2; public double X3; public NaiveVector4(double x0, double x1, double x2, double x3) { this.X0 = x0; this.X1 = x1; this.X2 = x2; this.X3 = x3; } public static NaiveVector4 operator *(NaiveVector4 l, double r) { return new NaiveVector4(l.X0 * r, l.X1 * r, l.X2 * r, l.X3 * r); } public static NaiveVector4 operator +(NaiveVector4 l, NaiveVector4 r) { return new NaiveVector4(l.X0 + r.X0, l.X1 + r.X1, l.X2 + r.X3, l.X3 + r.X3); } public double[] Data { get { return new[] { X0, X1, X2, X3 }; } } }

こんな風に。
レギュレーションはまあどうでもいいとして、元コードでどうやってキャッシュに乗らないようにしてたのかは知りたい。C/C++力がたりないので。(でも上みたいなエアツイートしかしてくれないんだったら本人の説明は期待できないな。っていうかもしこのあたりのツイートが自分宛だったとしたらただの的はずれですしね。)そんでもってご自身で128bit SIMD試してるけど、ますますレギュレーションって何かね?ですね。ツイートは関係なかったとのことでいいがかり申し訳ありませんでした。バグを修正した記事も書いていただきました。
セカオワFukaseの暗号をWebカラーで表現してみた
こんな記事(とツイート)を見た。
セカオワFukase、きゃりーが破局? 「暗号」ツイート前にも気になる投稿あった : J-CASTニュース
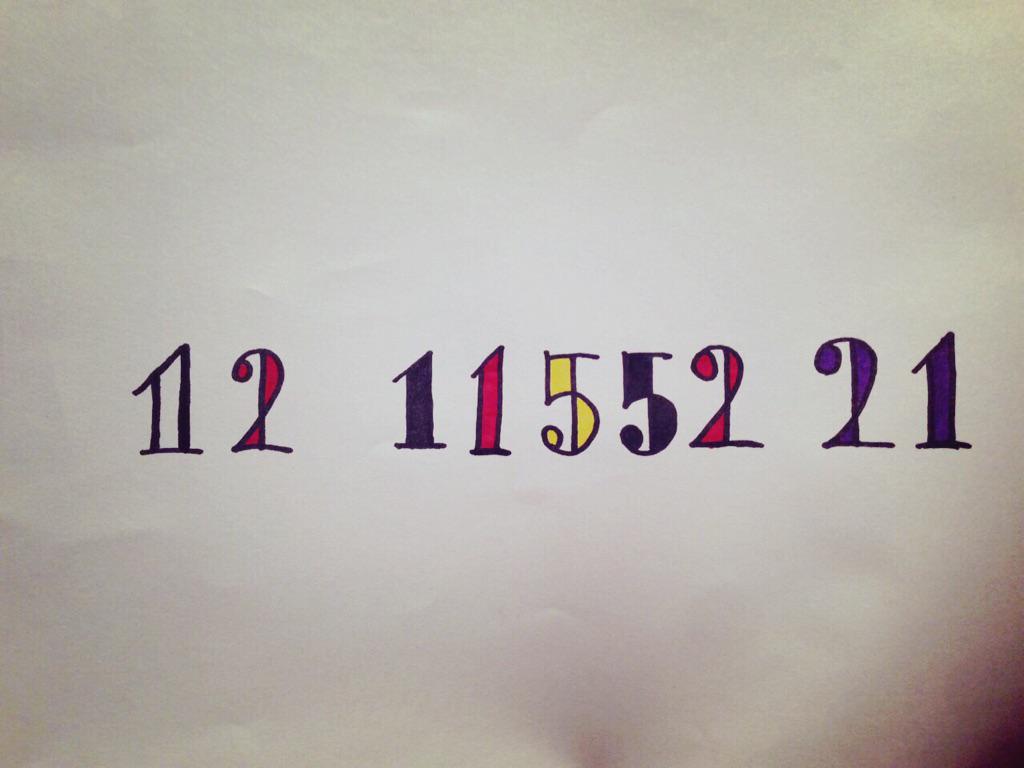
これを見てまず思ったのは、「これ全部のアルファベットを符号化はできないよな」だ。たとえば直感的には、“x”を色で表現するのは難しそうだ。聞いたこともないような色を使えばもしかしたら可能なのかもしれないけども。
次に思ったのは「色の名前ってどこかに定義されていないのかな……あ、CSSの色(Webカラー)があるじゃん」だ。
そこでWikipediaを見てみた。
すると、HTML4/CSS1に分かりやすい色が16色定義されていることが分かった。
| 名前 | 色 | 補足 |
|---|---|---|
| White | ||
| Silver | ||
| Gray | ||
| Black | ||
| Red | ||
| Maroon | マルーン/栗色 | |
| Yellow | ||
| Olive | オリーブ色 | |
| Lime | ライムグリーン | |
| Green | ||
| Aqua | 水色 | |
| Teal | ティールグリーン/鴨の羽色(かものはいろ) | |
| Blue | ||
| Navy | ネイビーブルー | |
| Fuchsia | フクシアの花の色/Webカラーとしてはマゼンタと同じ色 | |
| Purple |
これ、使えるな……
そこでできたのが、英文をWebカラーで暗号化するJavaScriptだ。
FUTARI NO OWARI - jsdo.it - Share JavaScript, HTML5 and CSS

右の「Text」のところに英文を入力して「Convert」を押すとFukase式暗号に変換される。
さすがに'White'を使うのはためらわれた(そういうフォントがないと苦しい)のでWhiteは抜いたが、残りの15色*1でアルファベット26文字のうち“j”、“x”、“z”を除く23文字をカバーすることができた。
なお、色を16色からX11の78色に広げたとしても、追加できるのは“j”だけで、“x”と“z”はやはりカバーできなかった。
ちなみに“j”が出てくる色名称は「NavajoWhite(ナバホ族の白、#FFDEAD)」でした。ここの背景のような色 だそうで。知らんわ!
*1:正確には、'Black', 'Red', 'Yellow', 'Lime', 'Green', 'Aqua', 'Teal', 'Navy', 'Fuchsia', 'Purple'の10色
ハイスピード通信的なやつ
Adventures in High Speed Networking on Azure | Age of Ascent
以前、ハイパフォーマンスASP.NETについてちょっと書いた時にTechEmpowerのベンチマークに触れたけど、
今回紹介する記事ではプレーンテキストのレスポンスに特化してあれこれ考察してる。